用神经网络帮妹子找对象
机器学习和深度学习入门
神经网络这个名词已经被人广为知道了,但是由于机器学习还是有一定的门槛。所以好多人想学而不得入其门,大部分的入门文章会给你解释一大堆专有名词的含义
我自己17年接触机器学习,后面几年没有太过深入研究。直到19年做推荐系统的需求才重新开始关注这方面的学习。目前人工智能已经是公认的未来10-20年的重点发展方向,所以我认为大部分人都可以了解一下什么是机器学习,以及机器学习到底能做什么。
我写这篇文章的目的其实就是希望能通过一个简单的例子来解答比较玄学的神经网络是怎么工作的
为什么我要选神经网络来做例子而不用其他的支持向量机或者卷积神经网络呢
因为神经网络算是传统机器学习和深度学习等更高级机器学习算法的一个交叉点
机器学习和深度学习
机器学习是一种对机器从数据中获得能力的算法的统称,深度学习是机器学习的一个子类。深度学习一定是机器学习,机器学习不一定是深度学习。
一般把基于决策树,支持向量机,近邻算法等这种传统数学的算法的叫做传统机器学习
而像卷积神经网络,循环神经网络等这种叫做深度学习。但是传统的神经网络则普遍被归类于机器学习的范畴,神经网络就成了从机器学习走向深度学习的一个很好的拐点,所以我认为学习神经网络具有比较高的性价比
从一个例子说起
假设现在有一个妹子去相亲,遇到了四个候选人,四个候选人分别在高,富,帅三个维度上的指标如下, 妹子对四人是否愿意交往的态度我们也做了调研, 现在想问的是如果有一个新的候选人小李, 我们想预测妹子对小李会是什么态度? 这个问题很有价值吧,我们现在就试图用神经网络解决这个问题
1 | 高 富 帅 是否愿意交往 |
我们先假设妹子一定是喜欢男孩拥有的某些特征, 所以才愿意交往的,我们有男孩子的3个属性的特征(高,富,帅)。我们先做几个基本假设
- 假设妹子对这三个特征的喜欢程度分别是 x, y, z, 而且喜欢程度跟名字无关
- 妹子是否同意跟男孩子交往是根据整体印象决定的,整体印象跟高富帅三个方面都有关系,妹子有自己的一套方法根据三个人的高富帅特征来评估整体印象
我们可以用如下伪代码来描述整个妹子评价男孩子的方法
1 | 妹子的评估方法( [高, 富, 帅], 妹子对不同特征的喜好程度) => 整体印象 |
- 妹子如果觉得整体印象合格就会同意试试交往
根据我们上面的假设我们可以得到如下流程
妹子观察一个人的特征 --> 在心里进行整体印象评估 -->根据评估结果决定是否同意交往
我们如果用程序描述以上流程就是
1 | # 获取男孩子的特征 比如小明的特征可以转换为 |
用程序来模拟妹子的整个评估过程
我们假设妹子对不同特征的偏好程序分别为 [x,y, z], 我们使用程序随机生成这个值
1 | import numpy as np |
以上w的结果是我们猜测的妹子对不同特征的喜好程度,这个喜欢程度肯定是不准的,但是不要紧,我们先看看根据我们猜的权重进行流程会是什么结果。我们要模拟妹子的评估过程还需要知道妹子怎么根据最终得分来判断是否愿意交往。
我们假设: 妹子是根据综合得分,综合得分超过一个阈值就同意交往。 但是我们也能猜到肯定是得分越高交往概率越大,得分越低交往概率越小,所以我们可以使用如下函数来作为妹子的整体印象评估函数: $y=\cfrac{1}{1+e^{-x}}$
妹子的评估函数形状大概如下图
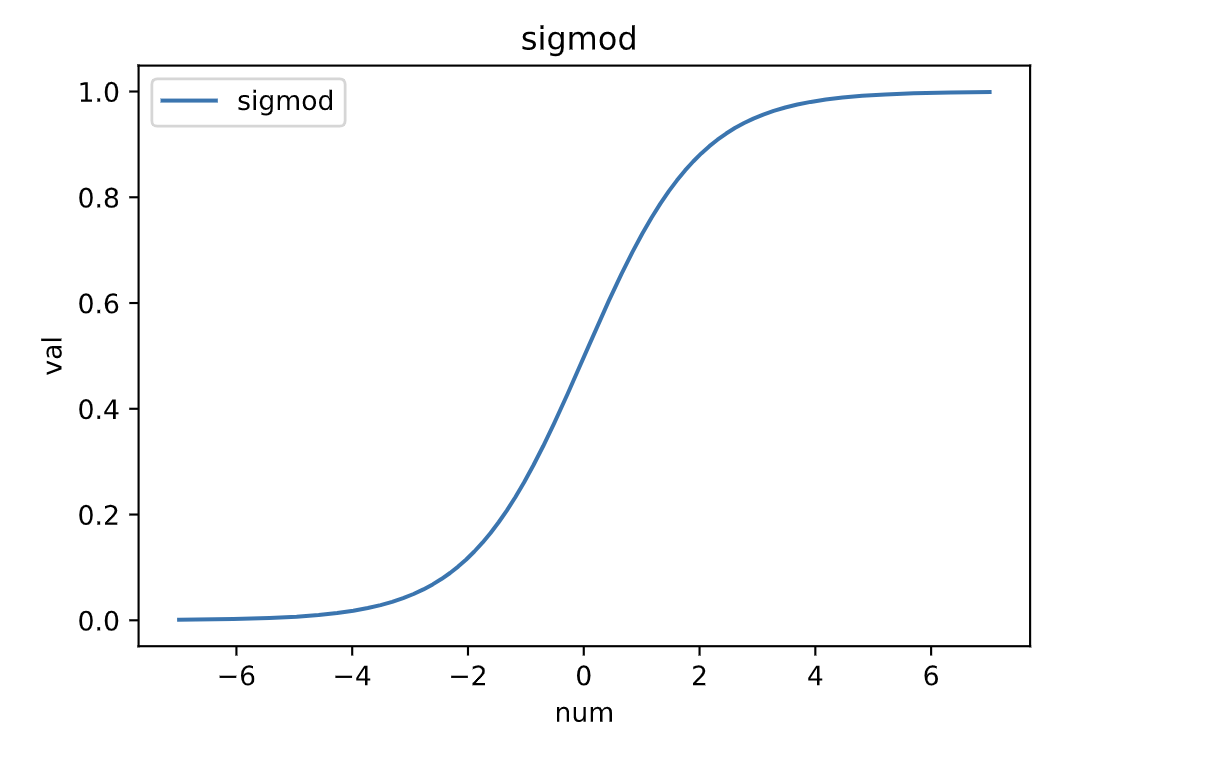
如此我们就可以写代码模拟过程了
1 | # 小刘的特征 |
根据上面的结果我们发现跟我们的预期不太相符合, 小明和小张也就算了,妹子对他们有好感,所以得分比较接近1。妹子明明不喜欢小刘,小赵,但是我们的程序给出了一个和小刘,小张差不多的结果。就是说我们预估的权重值不准确,也是嘛,毕竟权重是瞎猜的。
所以我们要根据我们已知的结果改进一下我们预估的权重
1 | # 所有男孩特征 |
我们发现结果变好了,为啥呢,小刘和小赵分数变低了,小明和小张分数变高了,他们之间差距变大,说明我们更容易区分妹子的喜好了。好的,我们循环纠正10000次然后试试预测小李
1 | for i in range(10000): |
哈哈,看我们的预测,妹子是会愿意跟小李交往的,这其实是符合我们预期的。因为我们发现这个妹子其实只看你是不是富, 你有钱我就跟你交往。 这说明我们的预测还是很准的,至少跟我们的直觉是一致的。
多层感知机(MLP)
前面这个妹子比较肤浅,只看富不富,假设有个妹子要求的条件比较多(比如又要富又要高),我们应该怎么处理呢
这种情况我们可以假设妹子看的条件变多了,妹子同时看多种条件,不只是高富帅三种基本条件还有 高富,富帅,高帅等组合起来的条件。那我们可不可以在造一个神经网络专门根据 高富,富帅和高帅这三个特征来处理呢? 当然是可以的。
但是我们不想自己制造高帅,富帅,高富这种特征数据了,我们已经可以根据高富帅其中的一个特征判断是否能赢得妹子芳心。我们思考一下,其实高帅,高富这种特征可以通过我们前面的神经网络求出来的。刚才妹子的判断其实就是一个判断是否富有的神经网络
1 | 高富 = 是否富(高富帅) x 是否高(高富帅) |
那我们预估一下,如果要生成高富,高帅,富帅我们需要几个简单的神经网络呢?
答案是2个基本的神经网络, 如下图
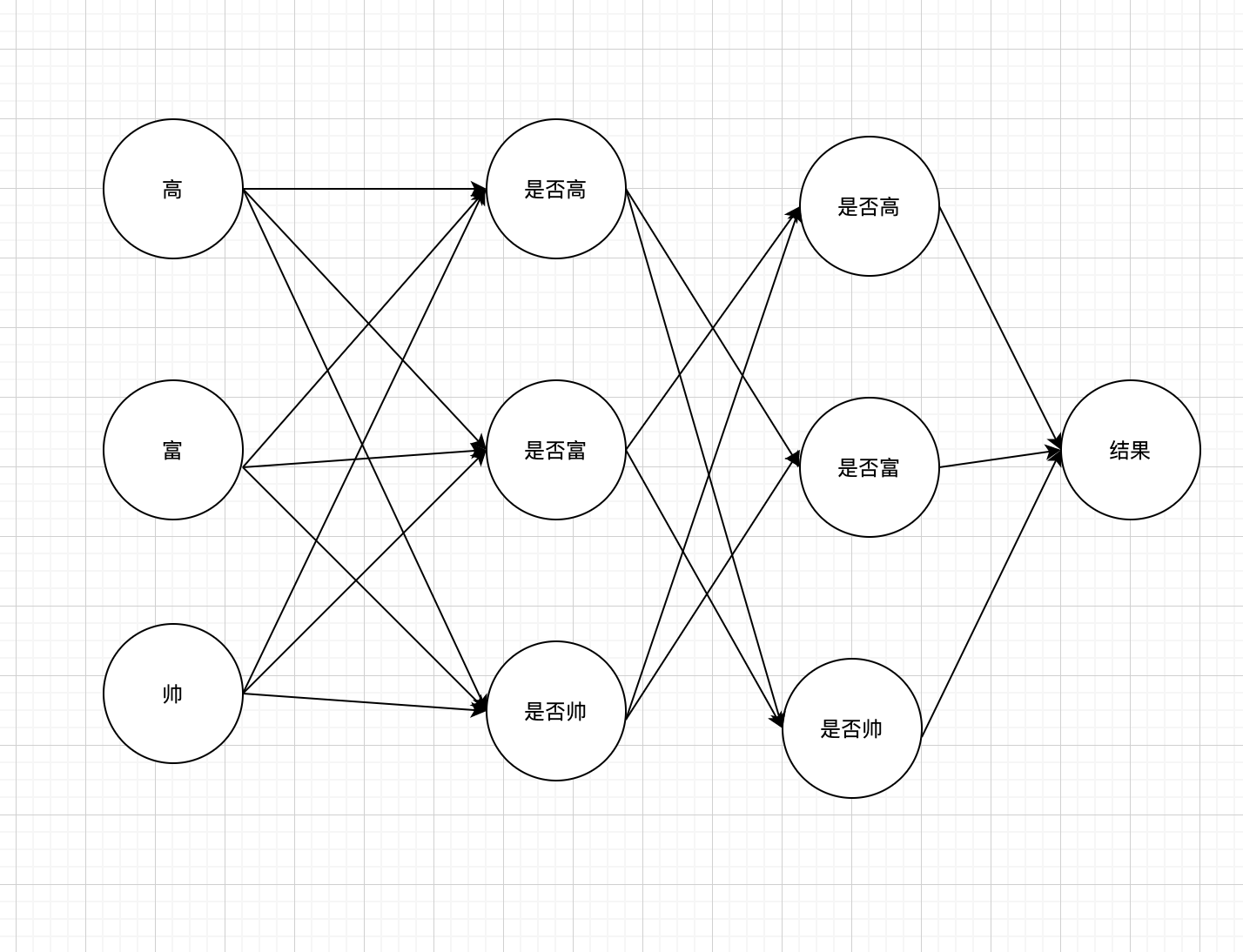
我们假设我们还有一组权重用于判断是否高富
1 | all_user = np.array([[0,1,1] |
结果符合我们预期,因为小李又高又富,符合我们假设的妹子的择偶需求,所以我们预估妹子给出了0.99的高分。
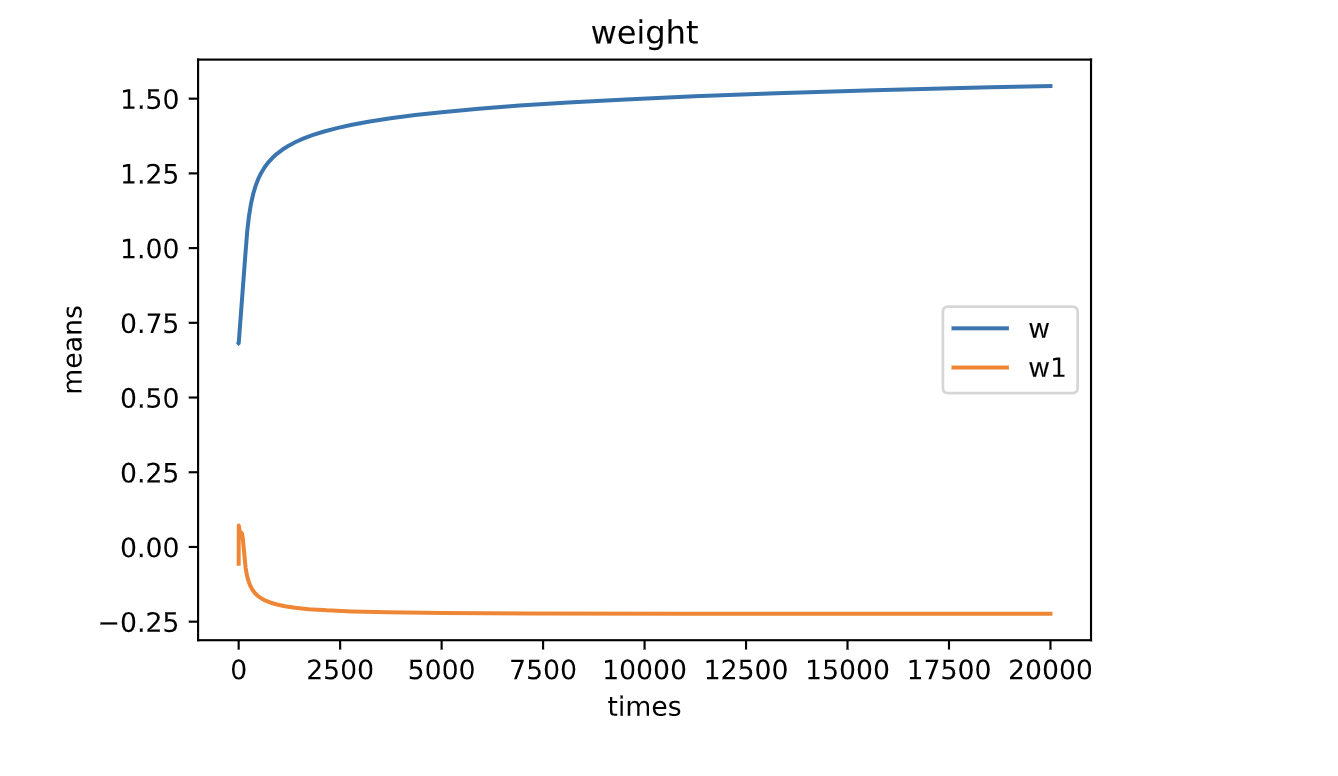
我们如果把权重的变化画出来,会发现权重的均值越来越稳定,这也正是我们要的效果
为什么要求导
上面的代码里面我们加入了一个 deriv函数, 这个函数其实是求sigmod上面的导数也就是斜率
我们之所以要求斜率,就是因为我们希望最终得分尽可能的往sigmod两端走,因为越往两端走,说明权重越稳定,预测结果越可靠。那我们就可以根据斜率来判断当前权重所处的位置。(通常机器学习会寻找一个函数用来衡量误差,这个函数叫做损失函数)
神经网络的迁移应用
很棒,我们已经学会了使用神经网络帮妹子择偶,哪怕妹子要求的特征很多,我们只要多加几个神经网络就可以了
其实使用神经网络预测很多其他的事情也是一样的道理,我们只要能提供够多的特征数据,神经网络就可以自动学习出来那些特征有用
但是我们上面的代码有一些地方其实是我们猜测的,比如: 我们猜测的权重,我们猜测的妹子评估的函数,我们猜测的评估误差的方法等,这些东西其实都是可以调整的,大家要记住这一点,只有整个流程是不变的,流程中的每一步都是有不同方法达成的
多分类的神经网络
上面我们已经设计了一个神经网络可以根据一个或者多个属性对特征进行分类。但是上面的分类结果只有2种,愿意或者不愿意,我们日常生活中经常会遇到多分类问题,比如判断一个图片是[0,1,2]中的哪一个数字
其实多分类问题可以转化为多个单分类的问题,转化过程如下
将上面的神经网络转换为三个神经网络分别用来判断 是否0,是否1,是否2, 结果为0就可以用 非1&非2 这个逻辑关系表示, 也就是说,多分类就是对单分类在进行一次带有逻辑关系的分类即可
方便的工具
sklearn
官网:https://scikit-learn.org/stable/
sklearn是一个机器学习的大集合,我们上面吭哧吭哧弄的神经网络别人已经帮我们搭建好了,我们直接使用就只需要几行代码,我这里拿sklearn里面的神经网络举例子。
1 | from sklearn import neural_network |
pytorch,Tensosflow,keras
这几个工具是偏向深度学习的工具,与前面的sklearn可以配合使用