基于kafka的延迟队列和优先队列的实现
背景
我们在业务中经常会有延迟队列或者优先级队列之类的需求。比如用户下单15分钟如果没有付款就自动取消订单。
延迟队列和优先队列本质上是一个需求,延迟队列可以看成一个使用时间作为优先级的队列。Kafka这种基于日志的消息队列并没有自带延迟队列的功能。所以如果想在Kafka的基础上实现此类功能,需要我们自己动手处理。我现在可以想到的实现方法有三种
- 消息分级
- 外存排序
- 针对延迟队列的时间轮
消息分级
先说简单的消息分级机制,假如我们遇到需要根据用户会员等级对不同等级的用户消息按照不同的优先级进行处理的需求。
最直观的办法就是我们制作多个等级的消息队列,每个队列对应一个用户等级的消息。或者在一个队列中使用多个不同分区,每个分区对应不同等级的消息。
这种方法本质上就是把不同优先级的消息内容分开存储。在消息被消费的时候按照优先级从高到低的方式进行处理。开源的rocketmq的延迟消息就是这种实现机制,其中的延迟消息队列内置了18个不同延迟时间级别的消息队列,客户端消费消息是从这18个队列中按优先级同时获取的。
按优先级分区处理图:
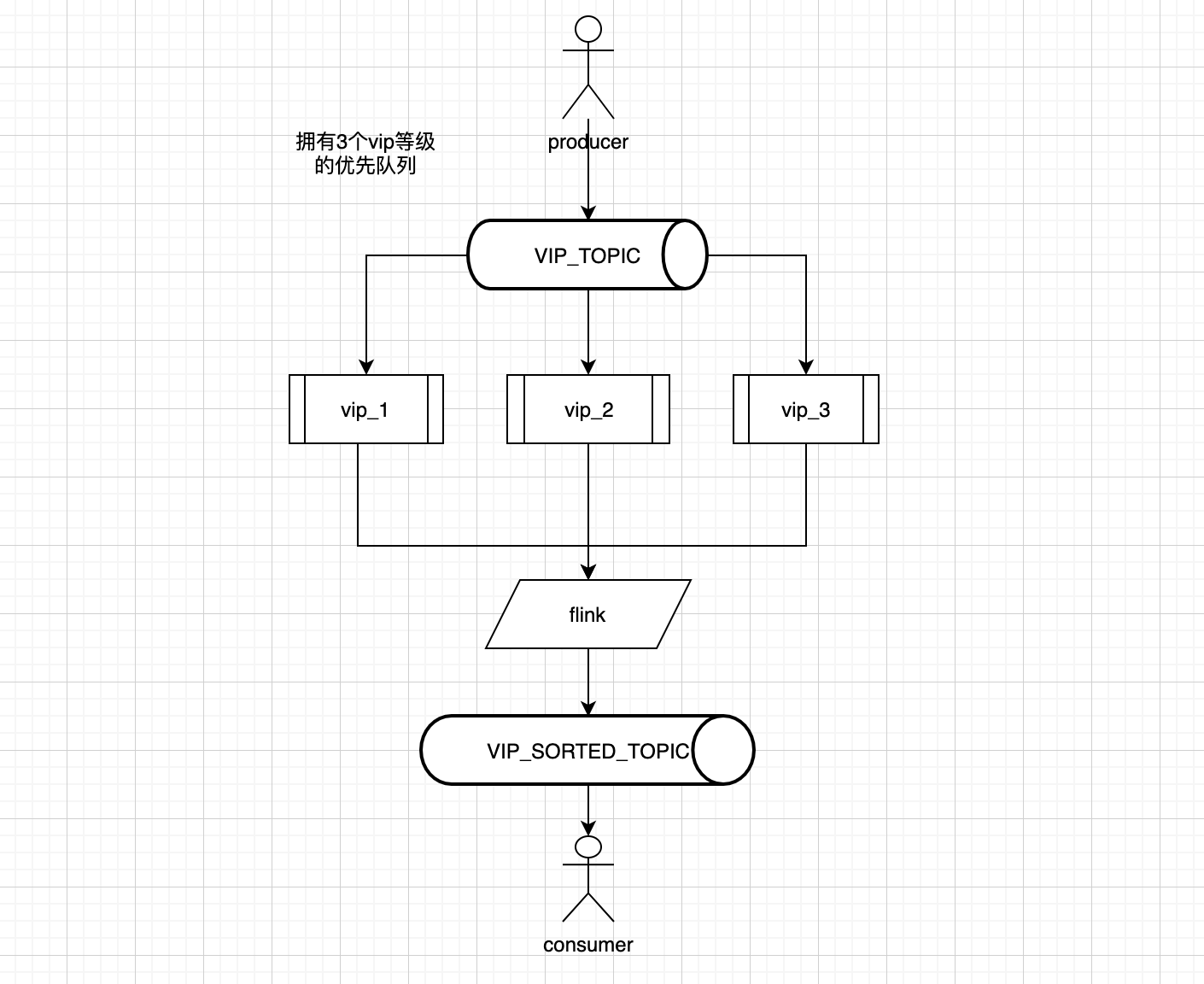
假设我们现在有3种用户优先级,我们需要按照一定的vip优先级顺序(假设vip等级 vip1 > vip2 > vip3)处理用户消息。具体流程如下
- 用户发送具有优先级的消息到vip_topic
- 分流程序实时消费vip_topic,将其中的消息按照优先级分别放入vip_1,vip_2,vip_3三个优先级队列, 这样一来,vip_1, vip_2,vip_3每个topic内部的消息都是保持有序的
- 另外有一个程序 每次按照 vip_1,vip_2,vip_3的顺序依次取消息进行处理,只有vip_1里面的消息处理完,才会处理vip_2里面的消息,最后处理vip3里面的消息。这样可以保证每一批次的消息都是按照 vip1> vip2> vip3的优先级进行处理
这种方法的缺点很明显,就是优先级区分受队列个数限制,只适用于优先级层级比较少的情况。如果我们想实现毫秒级的基于时间的延迟队列,那就要每个1ms区间都要构建一个队列出来,这种场景下明显不合理,所以采用类似方案的rocketmq开源版本仅仅实现了18个时间尺度的优先级队列。
外存排序
外存排序是真正的按照某种优先级字段对内容进行重新排序,然后再进行消费的手段。
我们可以先获取队列中的消息内容, 然后按照一定的优先级字段进行排序。最后按照排序后的结果进行消费即可。这种方法的技术难点在于如何利用小内存对大容量的磁盘内容进行排序。因为通常消息队列中的内容都是T级别的,而机器的可用内存空间往往是G级别的。
基于排序的优先级队列实现流程:
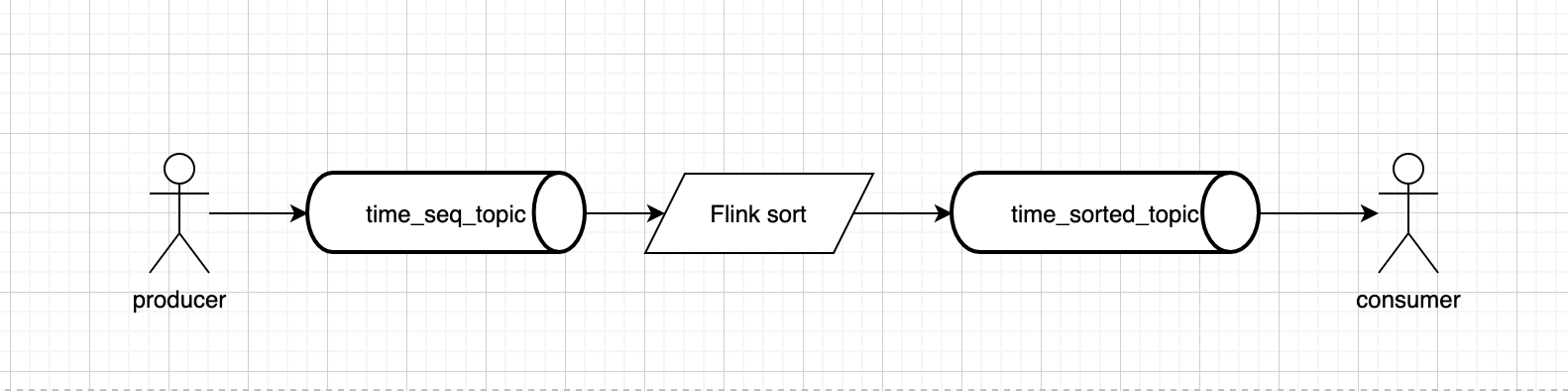
如何在2G内存的机器上对100G文件进行排序
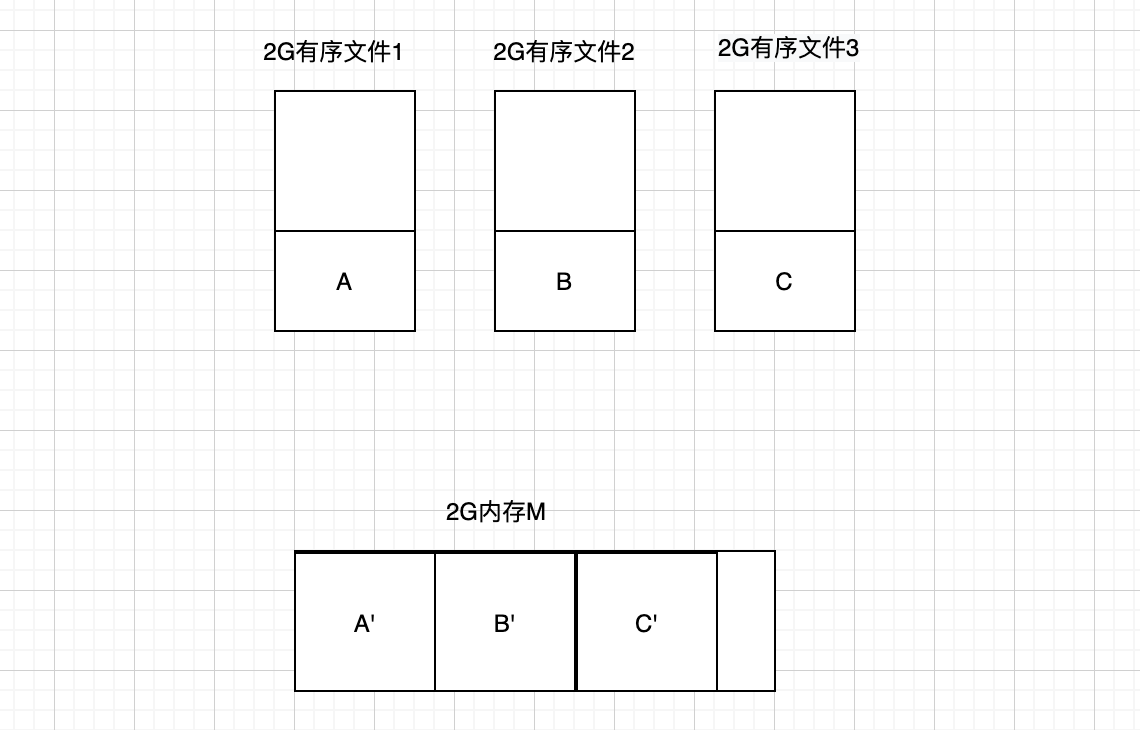
上图1
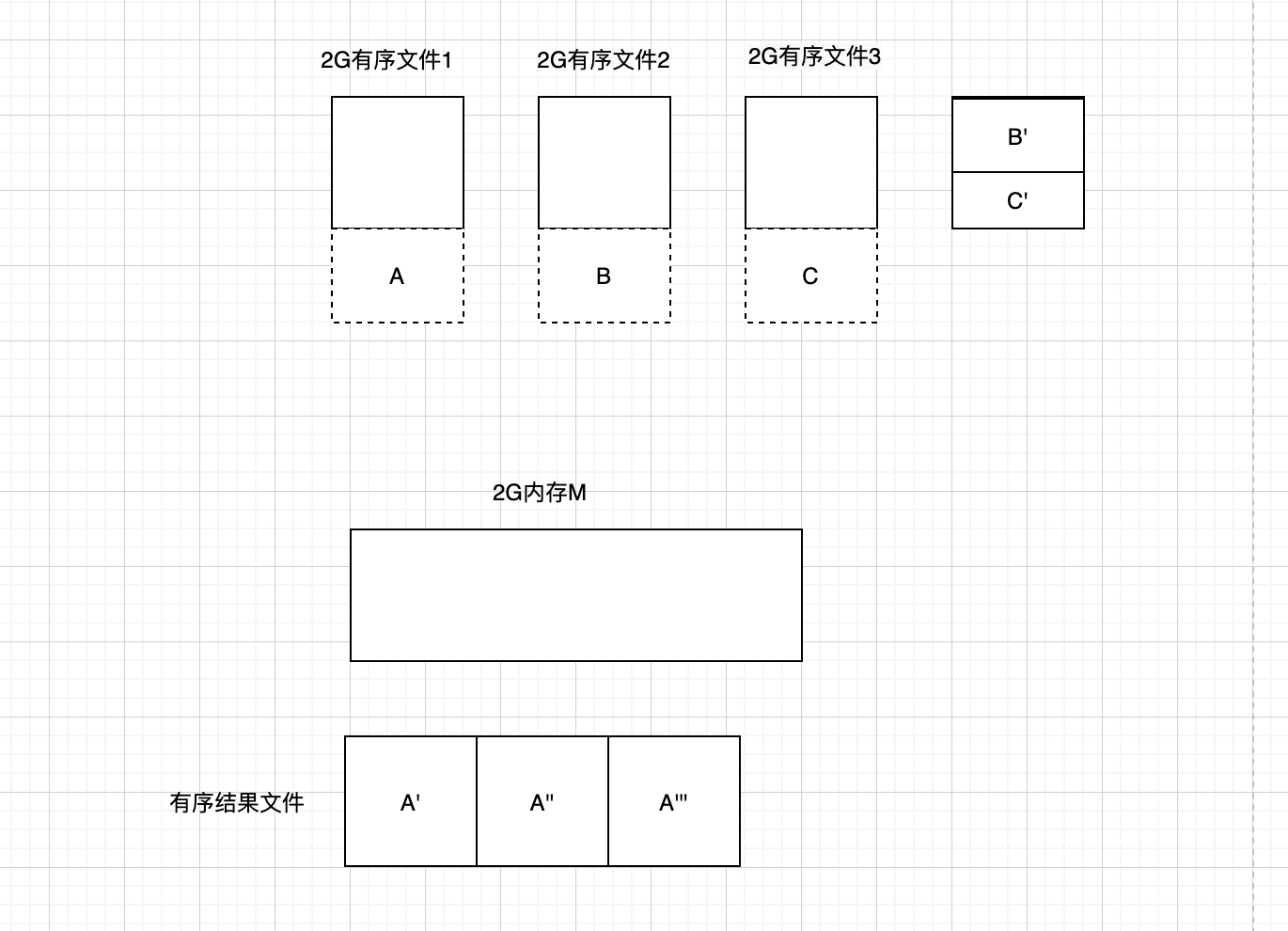
上图2
假设我们要对100G的内容在2G内存的机器上进行排序, 我们可以执行如下操作
- 使用split命令把100G文件分割成50个2G的小文件,并对每个分割后的文件使用sort排序(此时的问题已经变成对50个有序的2G文件在2G内存的机器上进行排序),(上图1 的有序文件1,2,3)
- 使用split取50个小文件的前40M数据,读取到内存进行排序,排序后的数据的前40M就是全局最小的40M内容(上图中的A,B,C三块文件读入内存变为A’,B’,C’, A’B‘C’在内存中排序后一定能得到全局最小的新A’)
- 将内存排序后的前40M内容输出到磁盘上,内存中剩余的1960M内容放回到磁盘,此时磁盘有51个1960M的有序文件(此时问题等价于对51个有序的1960M的文件在2G内存的机器上进行排序,途中的B’C‘被从内存中取出放回磁盘)
- 仿照上面的方法, 从51个文件每个读取35M内容进行排序,找出全局最小的35M内容
- 循环2-4步骤,直至所有内容都被排序成功
ps: sort,split 均为linux自带的命令可以对文件进行排序和分割,这个算法本质上还是多路归并排序, 但是相当于对归并排序做了一些优化:优化1,每段已排序数据一次取一批数据;优化2,没有采用记录文件指针的形式而是直接分割文件,操作更简单
如果我们可以在Kafka中采用实时程序对Topic中的消息进行外存排序,就可以得到我们需要的优先消息队列。但是在这个过程中我们还要注意使用kafka和Flink的事务机制,提供kafka端到端的事务保证,防止消息丢失
实现kafka+Flink的端到端的事务的方案在此不多叙述
针对延迟队列的时间轮机制
如果是仅仅为了实现延迟队而非通用的优先级队列,我们可以利用Kafka中的时间轮机制,将任务添加到对应的每一个时间分片中, 随着时间轮的驱动, 顺序处理每个时间分片其中的消息
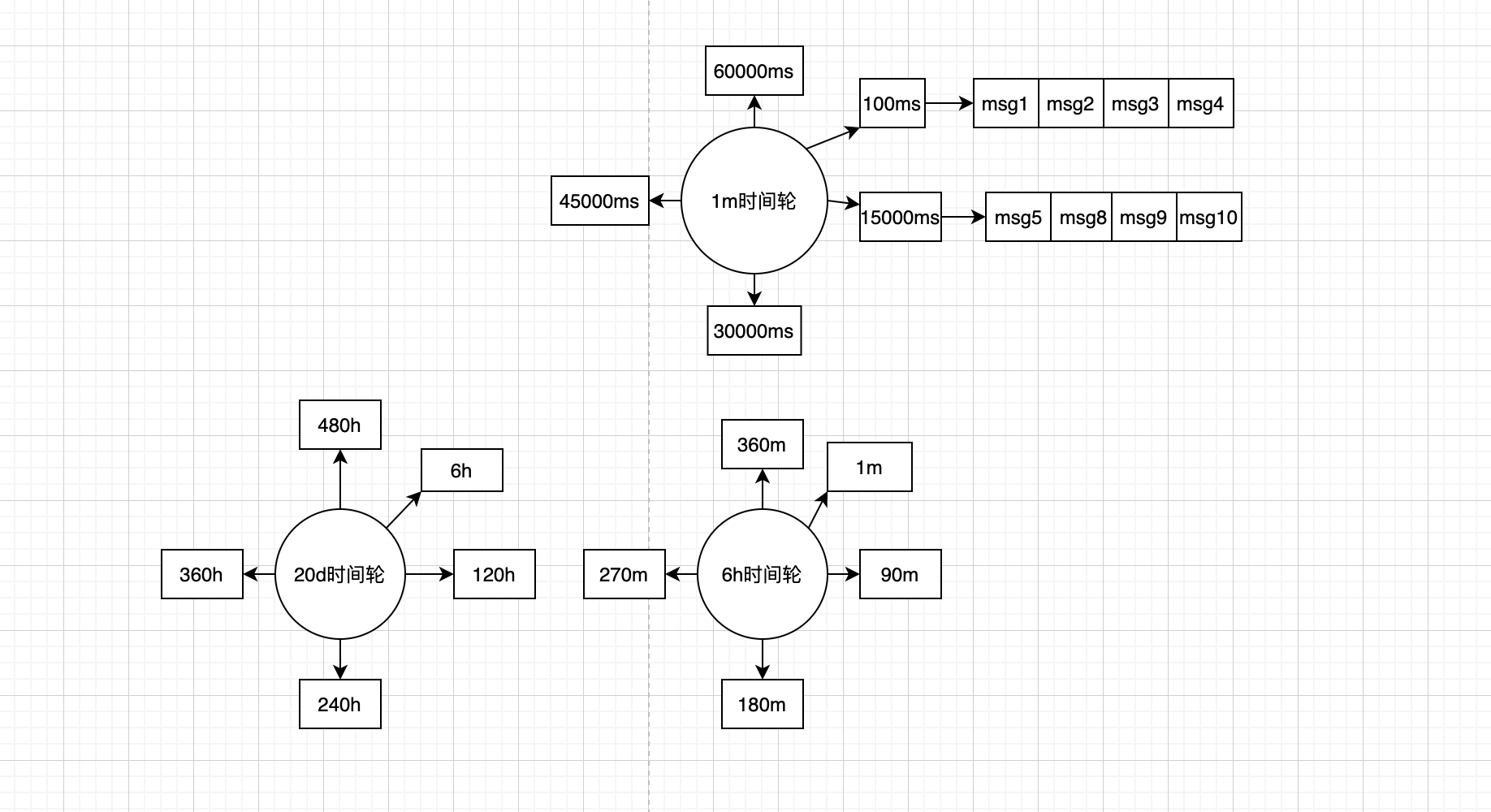
图3时间轮
时间轮是一种循环数据结构,时间轮中的每个槽位代表一个时间粒度,时间轮的时间粒度 = 槽位数量 * 每个槽位的时间粒度。时间轮由一个独立的循环程序驱动上面的当前时间指针前进。时间轮可以用槽位链表或者数组+消息链表的形式来实现。
用时间轮实现延迟队列具体方法如下
- 假设我们提供20d级别的延迟消息队列,我们需要提供3级时间轮,最低级是100ms粒度的时间轮,最大存储范围1min, 第二种是1min粒度的时间轮,最大存储范围6h,第三种是 6h粒度的时间轮,最大存储范围480小时
- 当一个消息进来,我们根据消息的延迟时间选择对应的时间轮分片进行消息插入,比如有一个延迟1500ms的消息,将会被插入到当前的1m时间轮的第15个槽位,如果消息的延迟时间为3h将会被插入更高一级的6h的时间轮的第3个槽位。
- 采用一个循环程序驱动时间轮转动并消费当前时间槽内的消息,当1m时间轮的所有消息消费完毕,从6h的时间轮中获取当前槽位的所有消息,并驱动6h时间轮指向下一个槽位,对取出来的消息排序补充入更低级的1min时间轮,继续驱动1min的时间轮继续消息处理。
- 采用类似手段可以通过控制时间轮的粒度,来控制延迟队列的粒度,达到一种较好的延迟队列实现方法
时间轮也有自己的缺点,不过在基于时间的延迟消息机制中已经是最好的解决方案了。但是这种方法不像上一种外存排序那么通用,仅适合于延迟队列这一种场景。
总结
其实以上三种方法我们本质上处理过程都是一样的,无非就是过程中我们使用的工具和排序机制不同。
第一种方法我们按照优先级分类,然后某个分类里面的消息天然有序, 我们取数据时候人为规定的字段优先级就充当了其中的排序机制。
第二种方法我们相当于按照消息接收的时间分类, 然后对优先级字段进行排序
第三种方法我们按照 延迟时间分类,然后对每一类里面的消息,让他变的局部有序。最后得到一个全局有序的结果。
如果把第二种方法里面的文件换成topic,排序方法换成按topicId排序的排序方法,就跟第一种毫无区别了。
同样,如果我们把第三种里面的时间轮上的槽位当作topic,也跟第一种方法没有什么区别
| 方法 | 适用范围 |
|---|---|
| 分区队列 | 实现简单,适用于数据量大,排序字段可选值较少的优先级队列和延迟队列场景 |
| 外部排序 | 实现复杂,需要端到端的事务保证,适用于排序字段可选值大,数据量较少的优先级队列和延迟队列场景 |
| 时间轮 | 实现复杂,仅适用于延迟队列场景 |