用户特征挖掘的方案
文中所有内容均以类似今日头条的内容平台做例子
整体流程
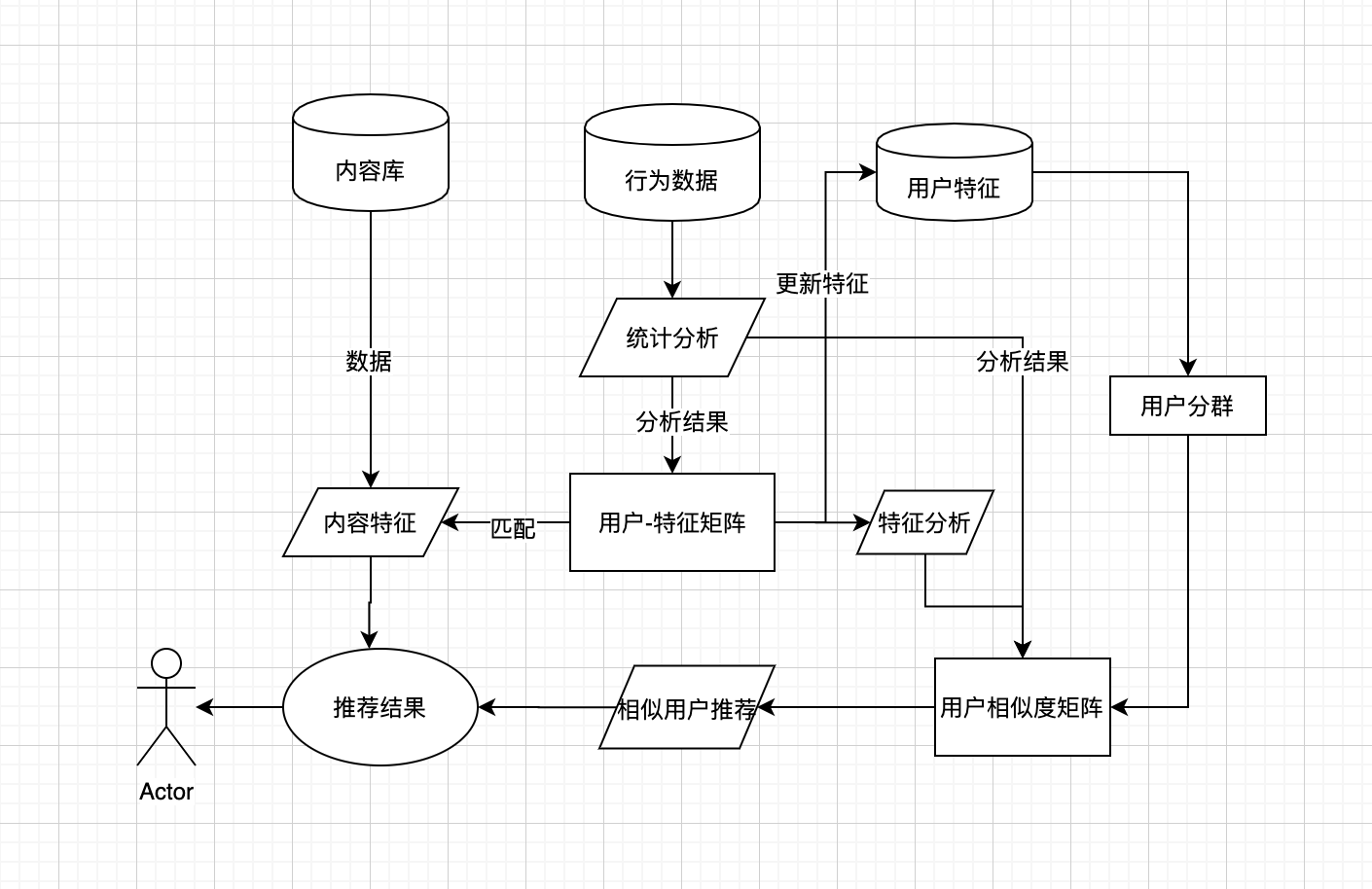
用户兴趣特征的挖掘
推荐系统所依赖的数据之中一类很重要的信息是用户到底喜欢什么,这个喜欢的标的物可能是某一类内容, 某一个人,某一个话题相关的内容等,我们需要做的事情就是尽可能的发现用户可能喜欢的事物标签。
其实用户的兴趣挖掘说难也难,说容易也容易。容易的地方在于很好入门,你只要知道一个序列的用户行为信息,就可以根据行为信息获得用户的部分兴趣特征。难的地方是你如果想要获得比较完整的,或者比较准确的用户兴趣,其实也是非常有挑战性的工作。
我想分享一点我自己在挖掘用户兴趣方面的想法和经验。
ps: 我们这里所提及的用户兴趣统统是指用户的隐式特征,就是从用户行为中提取的非主动操作的信息
行为数据-用户特征矩阵-内容特征匹配
假设我们拥有一段用户的行为信息序列, 我们可以非常简单的统计出来用户经常观看的文章。
但是我们不能向用户推荐已经看过的文章, 所以我们需要挖掘用户观看某文章背后的潜在信息, 并给用户推荐内容比较相似的或者关键词比较相关的文章内容。
用户特征矩阵的生成
比如:我们可以基于用户观看的文章背后的标签出现次数进行分数统计,标签每出现一次记一分,获得一个用户对标签的喜好表。如下
| 用户 | 新冠肺炎 | 金融政策 | 李大霄 | 新闻资讯 |
|---|---|---|---|---|
| 1 | 5 | 6 | 0 | 1 |
| 2 | 2 | 0 | 9 | 3 |
| 3 | 3 | 4 | 3 | 1 |
| 4 | 0 | 5 | 4 | 9 |
从上面我们可以知道用户1喜欢 金融政策和新冠肺炎相关的内容,用户2可能是李大霄的粉丝,喜欢看李大霄相关的文章。
为了获取这个列表我们也可以根据用户对不同内容标签的点击率进行归一化的分数统计, 取点击率比较高的标签。一样可以得到蕾丝上面的**<用户, 特征,喜好程度>**的三元序列
根据特征矩阵进行内容推荐
然后我们就可以根据未推荐文章中出现的用户喜欢的特征和特征权重对不同文章进行计分, 对内容综合积分,按照分数进行排序输出。
| 文章 | 新冠肺炎 | 金融政策 | 李大霄 | 新闻咨询 |
|---|---|---|---|---|
| A | 0 | 3 | 1 | 0 |
| B | 1 | 0 | 1 | 2 |
假设我们有A,B两篇文章,内容标签如上。我们可以对用户1, 2与内容的匹配程度进行分值计算。可以得到如下表格
| 用户/文章 | a | b |
|---|---|---|
| 1 | 3 x 6 = 18 | 5 x 1+ 2 x 1 = 7 |
| 2 | 9 x 1 = 9 | 1 x 2 + 1 x 9 + 2 x 3 = 17 |
很容的知道应该给用户1 推荐 A 文章, 给用户2推荐B文章。
我们也可以采用其他的综合考虑权重的计分方法, 但是核心要点都是两个,一个是获得用户与特征的矩阵, 一个是获得内容和特征的矩阵。鉴于计算量巨大,可以使用 矩阵相乘的算法进行加速。
行为数据/用户特征-用户相似度-内容推荐
我们也可以根据用户经常观看的信息, 寻找与用户比较相似的用户群体,然后假定用户与相似的用户群具有相似喜好, 从用户群体的共同喜欢内容中挑选出来一些用户未观看的推荐给用户
计算用户的相似用户
我们使用Jaccard系数来表征用户的相似度
- 使用用户行为计算相似度
我们可以使用用户行为信息如此计算两个用户的相似度
$$Y(similar)=\cfrac{U1 ∩ U2}{U1 ∪ U2}\tag{1}$$
使用用户1 和用户2 的观看内容中相交的部分 / 用户1 和用户2 内容的并集, 能得到两个人都喜欢的内容,在两个人观看总内容的一个比例
- 使用用户特征计算相似度
我们也可以通过用户身上的标签,比如 ,使用的手机型号,年龄,性别,地区等信息。 一样采用如下公式进行用户标签相似度的计算。计算结果与上面用户行为相似度结果一样
$$Y(similar)=\cfrac{U1 ∩ U2}{U1 ∪ U2}\tag{1}$$
根据相似用户进行推荐
这个比例可以作用两个用户相似度的评价标准, 拿到用户的相似用户集合以后,通过统计相似用户已观看列表中的的内容的出现次数。可以得到如下表格
| 用户/内容 | A | B |
|---|---|---|
| 1 | 5 | 2 |
| 2 | 9 | 1 |
选择出现次数多的进行推荐即可。
也可以进一步利用相似用户的内容出现次数,通过统计去更新用户的特征矩阵中的(用户->特征)的分值。然后再根据特征的加权获取最终的推荐结果
用户数据-用户特征-用户分群-用户相似推荐
我们也可以根据用户本身的特征,对用户进行分类。例如:女性用户,30-35岁, 使用安卓手机,经常在晚上6-9点使用app等特征对相似的用户进行分群
然后统计分析该分群用户的行为记录。采用类似于上面用户相似度的统计方法,获得用户对内容或者对特征的分数矩阵结果
综合方案
我们在实际的生产中可以综合以上各种策略, 获取用户的特征矩阵并对内容进行计算分数。在根据实际场景中的效果进行不同权重和比例的动态调整。
一般来说是可以获得不错的效果的。