Google-Bigtable学习记录
Google Bigtable
本文希望能解答如下问题
- Bigtable产生的原因是什么,解决了什么问题
- Bigtable是怎么解决这些问题的
- Bigtable当前采用的方案有什么优点和不足
GFS的限制
GFS是谷歌的分布式文件系统,提供了基础的分布式存储和读写服务,解决了大规模的数据的存储和使用的问题。但是由于GFS接口过于底层,内部存储的都是纯粹的二进制文件数据。Google希望提供一个具有结构模型的数据库产品以方便上层业务易于使用分布式数据存储服务
数据模型
Bigtable 是一个稀疏的、分布式的、持久化存储的多维度排序 Map。Map 的索引是行关键字、列关键字以及时间戳;Map 中的每个 value 都是一个未经解析的 byte 数组。
map的key是以 <row, column, time> 为综合key的字符串
1 | (row:string, column:string,time:int64) -> string |
之所以采用这个一个简单的模型主要原因有以下几个
- 足够简单灵活,可以满足大多数的数据存储需求
- 足够可靠
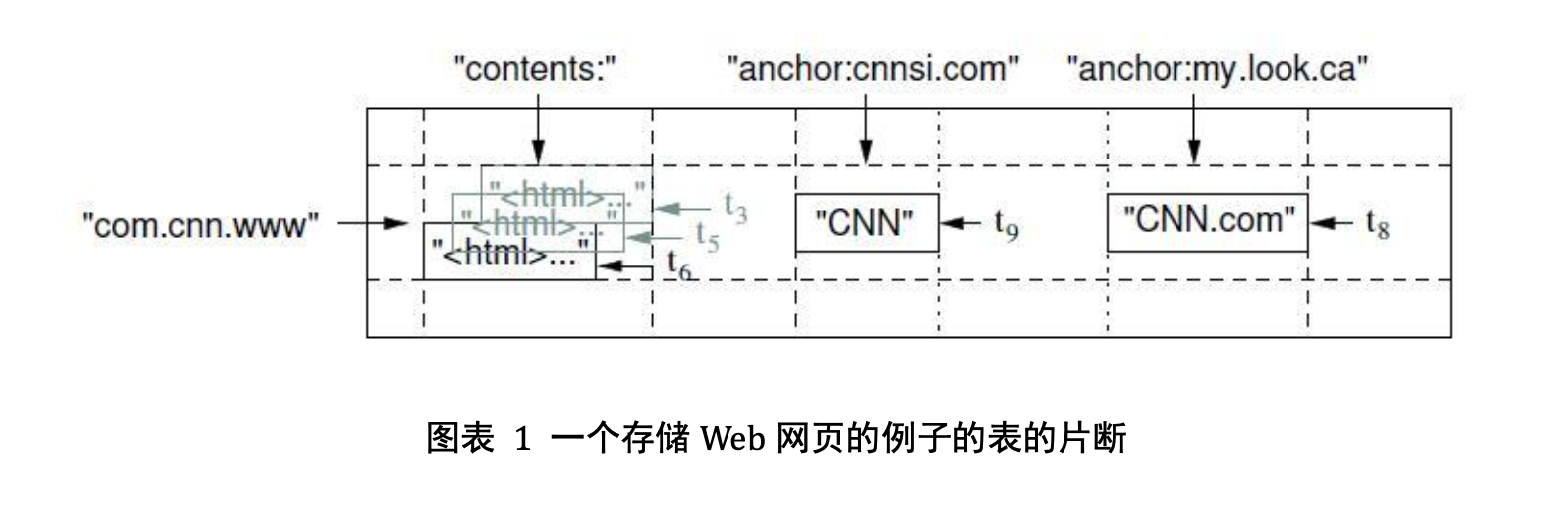
这套k-v模型看起来简单, 却足以表达我们的其他表模型, 例如如下表格-table1
| rowkey | info:name | info:age | meta:status |
|---|---|---|---|
| 1 | 小明 | 19 | 1 |
| 2 | 小红 | 17 | 0 |
| 3 | 小刚 | 13 | 1 |
像上面的一个常见的二维表格在Bigtable中我们可以使用如下方式表示
1 | table1:1:info:name -> 小明 |
上面3个条记录共同构成原表中的rowkey为1的一行记录
行
表中的行关键字可以是任意小于64k的字符串,同一个行关键字的读或者写都是原子性的。上述的例子里面我们就可以把1/2/3作为行关键字。某种意义上,行关键字类似于传统数据库中的主键ID。
Bigtable中的数据拆分是按照行关键字来进行的,也就是说,如果我们有3个数据节点, 1 , 2, 3这三条记录可以被被分到不同的机器上面
列族
我们上述的表中的INFO和META就是列族, 图表1 中的anchor也是列族的体现。 列族必须提前创建。列族下还可以含有多个列,像NAME和AGE就同属于一个列族下面的不同列。
列族的存在是为了方便对数据进行压缩
时间戳
在 Bigtable 中,表的每一个数据项都可以包含同一份数据的不同版本;不同版本的数据通过时间戳来索 引。Bigtable 时间戳的类型是 64 位整型。Bigtable 可以给时间戳赋值,用来表示精确到毫秒的“实时”时间; 用户程序也可以给时间戳赋值。
如果应用程序需要避免数据版本冲突,那么它必须自己生成具有唯一性的时间戳。数据项中,不同版本的数据按照时间戳倒序排序,即最新的数据排在最前面。
接口约定
客户程序可以对 Bigtable 进行如下的操作:写入或者删除 Bigtable 中的值、从每个行中查找值、或者遍历表中的一个数据子集。
Bigtable 可以和 MapReduce一起使用,MapReduce 是 Google 开发的大规模并行计算框架。Google已 经开发了一些 Wrapper 类,通过使用这些 Wrapper 类,Bigtable 可以作为 MapReduce 框架的输入和输出。
Bigtable架构
Bigtable是建立在其它的几个Google基础构件上的。BigTable使用Google的分布式文件系统(GFS)存储日志文件和数据文件。
刚才提到的列族就是Bigtable存储的文件单位, 同一个列族的信息会被整合成一个SSTable文件,会随着rowkey分布到不同的机器上。多个SSTable会由索引文件来定位数据,也可以被加载到内存,通过二分查找查找其中的有序数据。
BigTable 还依赖一个高可用的、序列化的分布式锁服务组件,叫做 Chubby。一个 Chubby 服务包括了 5 个活动的实例,其中的一个实例被选为 Master,并且处理请求。
Bigtable 包括了三个主要的组件:链接到客户程序中的库、一个 Master 服务器和多个 Tablet 服务器。针 对系统工作负载的变化情况,BigTable 可以动态的向集群中添加(或者删除)Tablet 服务器。
Google使用一个三层的、类似B+树的结构存储 Tablet 的位置信息
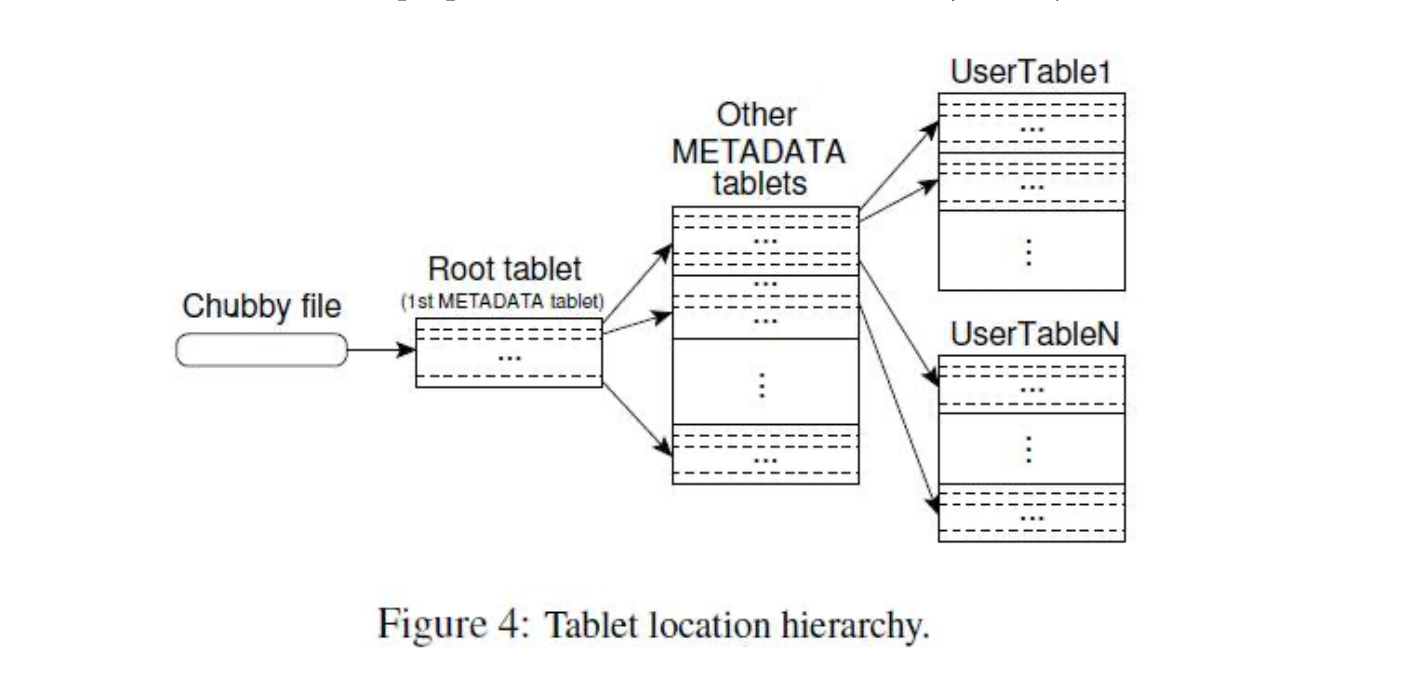
第一层数据在chubby中,提供root tablet的位置信息。
Bigtable读写流程
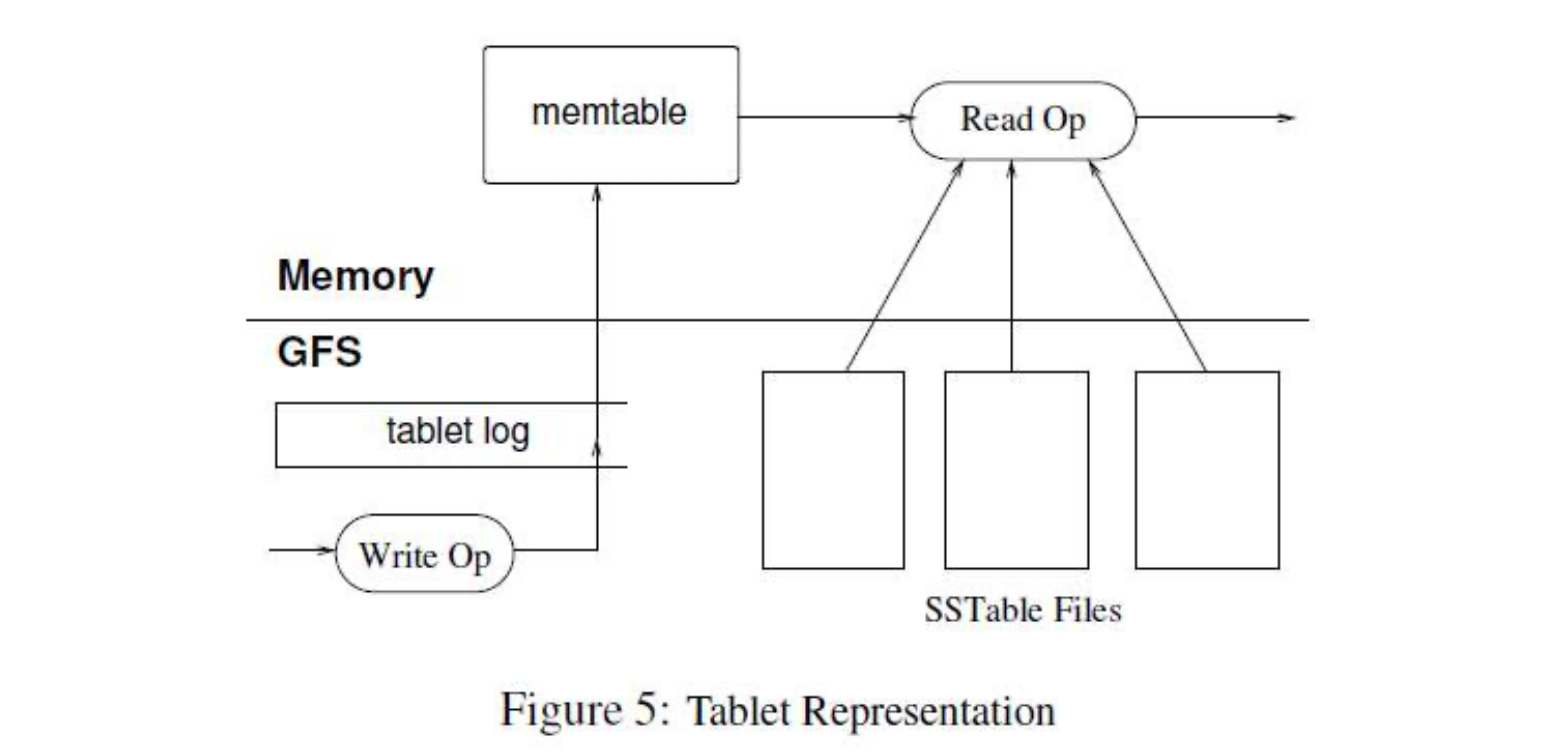
Bigtable采用LSM树的形式进行读写操作,新数据先写入日志文件和内存,等内存达到一定数量或者一定时间在将内存中的数据固化到磁盘。 读取的时候先读区内存中的数据, 如果内存中没有要找的数据,返回磁盘进行逐级向上的查找。
写入日志的存在是为了防止机器挂掉以后内存数据的丢失
Bigtable怎么解决一致性,可用性和分区容忍性
Bigtable构架于GFS之上, Bigtable本身并没有提供备份或者主从副本的方案。所以Bigtable依赖于GFS提供一致性和可用性保证。
开源的Bigtable实现
Hadoop系列中的Hbase一般被认为是bigtable的开源实现,两者采用了相似的设计思路,适用场景也大部分重合。还有一个Cassandra也拥有类似的功能不过在部分设计思路上有很大不同,有兴趣的读者可以自行研究